Welcome to OneContext!
What is OneContext?
OneContext makes it really easy to compose and deploy custom RAG (Retrieval Augmented Generation) pipelines. RAG makes it possible to augment large language models with domain-specific knowledge, without the expensive fine-tuning step.
How does it work?
OneContext is made up of three key components: knowledge bases, pipelines and vector indexes.


-
Knowledge Base : A knowledge base is where you store your files. Think of this as a folder, you can upload and delete files from a knowledge base.
-
Vector Index : A vector index is a collection of chunks (processed parts of a file) with associated vectors. These indexes allow for efficient semantic search based on vector similarity.
-
Pipeline: A pipeline is a collection of
steps1. You can chop and change between a wide variety of pipelines just by swapping in and out variousstepsin your pipeline. For example, a typicalingestionpipeline starts off with a Preprocessor step to go from files to text, then through a Chunker step to split the text into chunks, then through a SentenceTransformerEmbedder step to convert the chunks into embeddings, and finally through a ChunkWriter step to save those embeddings to a Vector Index. Another example of a pipeline would be aquerypipeline, which can be used to define custom query logic, again, via composition ofsteps, to let your retrieve and process chunks from a vector index to provide context to your LLM application at runtime.
For more, see a technical treatment here, and a blog post here
What makes OneContext different?
Outrageously fast
OneContext runs every single step of your pipeline in the same VPC, with a
hot GPU cluster attached. That means; no network latency between your
punctuation model, your embedding model, your Vector DB, your reranker model,
and any other node you want to add to your RAG pipeline.
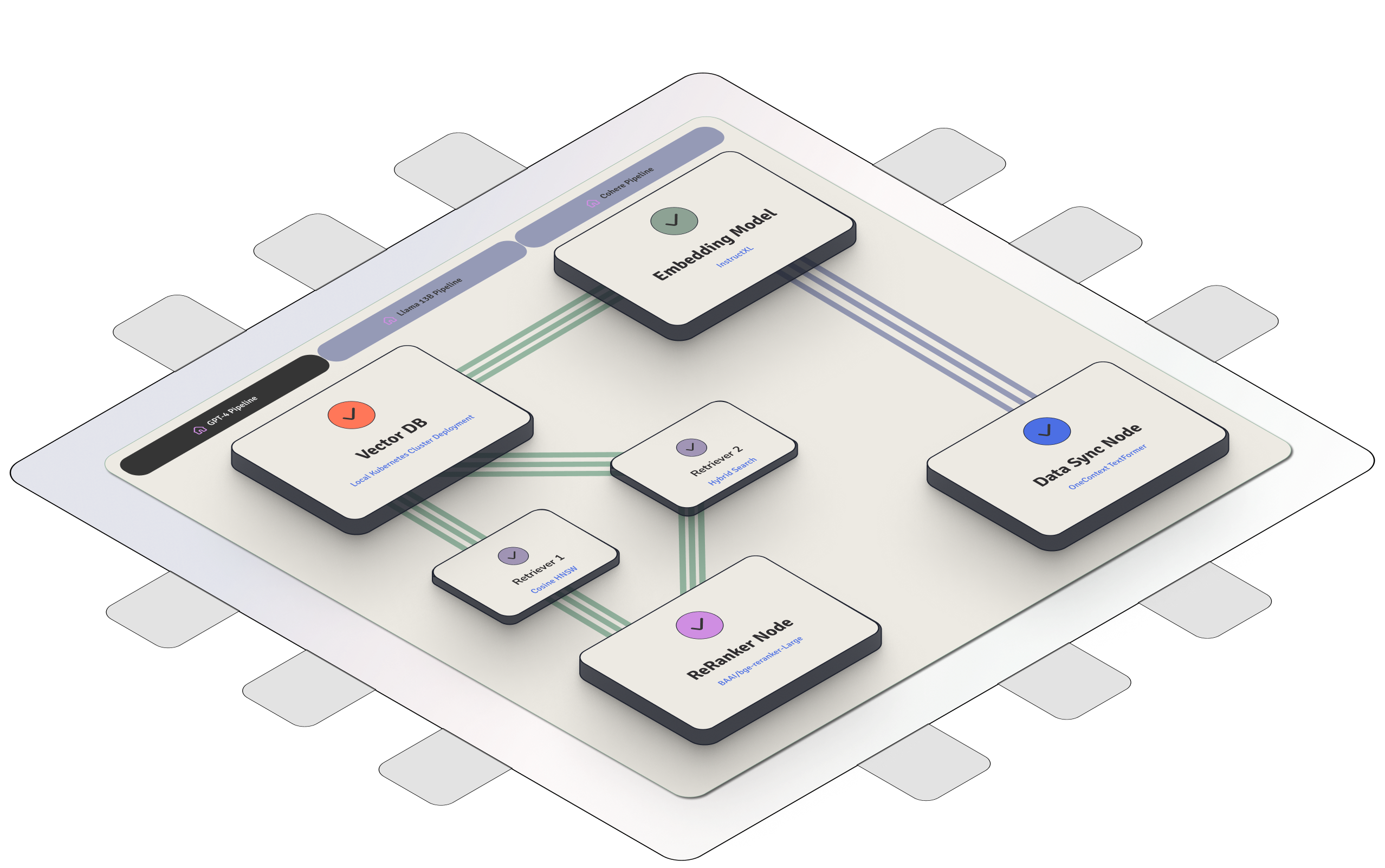
To learn more about the latency benefits, you can check out our blog-post here.
Evaluation built in
Evaluating RAG pipelines is hard. How can you iterate and try and improve something when you don't know what "good" looks like? We are trying to solve that problem, at OneContext.
For customers on our dedicated plan, customers can upload "test sets" for things like truthfulness, recall, and precision. These tests get run every time a new pipeline is deployed, and our customers instantly see the improvement (or dis-improvement) in the new pipeline.

Version Control
OneContext makes version control of RAG pipelines much easier. In most enterprises' code-bases, the logic of their RAG pipeline is too tightly coupled with their business-logic. This makes version control difficult, because it's not as simple to roll back an atomic change in a RAG pipeline, rather, engineers end up re-doing the plumbing into the business-logic each time.
OneContext fixes this by allowing users to define their entire RAG pipeline in one YAML file, and then run it from anywhere. Defining the RAG pipeline logic declaratively in one file, allows for a complete separation of concerns between RAG pipeline logic, and application logic.

Dead simple
Adding, removing, and changing steps in a pipeline is as
simple as editing a YAML file. OneContext automatically spins up an entirely
new deployment for you, on a Ray cluster, with auto-scaling, and GPU
acceleration.
We make it really easy for you to iterate on your RAG pipeline, which means you can concentrate on building the best product for your users, and not worry about deployment or infrastructure.
Get started today
Get started with the serverless plan in under 10 minutes. It comes with 2,500 free credits for you to try out our platform, no commitments or credit-card details required. If you run out credits, you can easily buy more, and your credit balance will decrease according to the amount of compute you ask of the cluster.
Once you're happy seeing just how much time OneContext can save your engineering team, you contact us to set you up on our dedicated plan, and we'll deploy a custom cluster in your compute environment, with any model you want, and we'll charge you one fixed price per month going forward (no more usage based billing).